All samples on this page are from a VQ-VAE learned in an unsupervised way from unaligned data. More details in the paper.
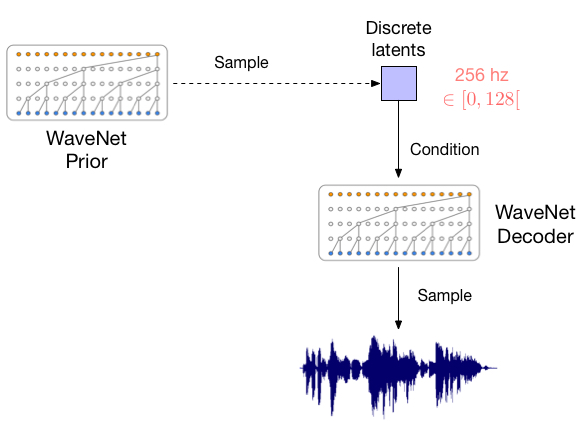
These samples are reconstructions from a VQ-VAE that compresses the audio input over 64x times into discrete latent codes (see figure below). Both the VQ-VAE and latent space are trained end-to-end without relying on phonemes or information other than the waveform itself. Although the reconstructed waveforms are very different in shape from the originals, they sound very similar.
Originals and reconstructions
The discrete latent space captures the important aspects of the audio, such as the content of the speech, in a very compressed symbolic representation. Because of this we can now train another WaveNet on top of these latents which can focus on modeling the long-range temporal dependencies without having to spend too much capacity on imperceptible details. With enough data one could even learn a language model directly from raw audio.
Samples
When we condition the decoder in the VQ-VAE on the speaker-id, we can extract latent codes from a speech fragment and reconstruct with a different speaker-id.
The VQ-VAE never saw any aligned data during training and was always optimizing the reconstruction of the orginal waveform. These experiments suggest that the encoder has factored out speaker-specific information in the encoded representations, as they have same meaning across different voice characteristics. This behaviour arises naturally because the decoder gets the speaker-id for free so the limited bandwith of latent codes gets used for other speaker-independent, phonetic information.
In the paper we show that the latent codes discovered by the VQ-VAE are actually very closely related to the human-designed alphabet of phonemes.
Originals and reconstructions with different speaker-id
Bonus!